How to Scrape Chinese Web at a Large Scale – Real Case from DataOx
Learn why web scraping is ideal for
product data extraction from e-commerce platforms.
Consult DataOx on how to scrape Chinese web.
Ask us to scrap the website and receive free data samle in XLSX, CSV, JSON or Google Sheet in 3 days
Scraping is the our field of expertise: we completed more than 800 scraping projects (including protected resources)
Table of contents
Estimated reading time: 13 minutes


Introduction to Chinese Web Scraping
In our modern, progressively digitized reality, every industry tends to become more and more data-driven, and the analysis of large amounts of data is especially crucial for the eCommerce sphere, which constantly grows and has no boundaries.
To get insights from one of the largest markets in the world, you might need to scrape Chinese web, i.e. Alibaba, TaoBao, and other websites and apps.
How to Scrape Chinese Web
When you gather data from various sources, you receive a crucial piece of competitive intelligence and the potential to win over the other market players in your field.
Today, arming yourself with the necessary information is simple. Ecommerce data scraping completes this task quite effectively, and when it comes to fetching publicly available information from e-commerce giants like Amazon, large-scale web scraping is the best approach. Scraping websites on a large scale involves running multiple scrapers in parallel against one or more websites and extracting massive amounts of data.
Speaking about web scraping at a large scale, we have plenty of cases to share, including a really huge project for a customer from Shanghai in product review scraping.
Chinese Web Scraping Real Case
Project
Our client was hired by one of the most well-known brands in the Asian region, and he needed to gather reviews from major leading e-commerce platforms in China for an effective marketing strategy. He turned to web scraping specialists from DataOx to cope with the challenge.

The task to scrape Chinese web
The task of the DataOx team was to provide our client with the product data and reviews we scraped from.
- Tmall formerly Taobao Mall;
- Jd;
- PDD;
- Kaola.
Idea
The idea was to gather all this data and, through an AI-based solution, analyze it to:
- Make sentiment analysis;
- Improve the products;
- Increase sales;
- Improve brand awareness;
- Enhance customer satisfaction.
Challenges
It’s no wonder that the process of scraping the above-mentioned Chinese e-commerce giants for such an enormous scope of data was full of challenges and pitfalls that we successfully overcame.
To give you an idea, we’ll mention some of them below.
Login requirements
To login into the target sites, we needed a Chinese mobile phone number, so we had to get one and log in on the websites under a Chinese IP.
PDD is a platform with only a mobile version, so we found a Chinese provider to enter the site under a Chinese IP as well.
Mobile app scraping
Since PDD is mobile-based only, we had to create a turnaround and scraped the platform with the help of a mobile app developed for this purpose.
Captchas
Almost all of the sites we scraped had various captcha types for each page, most of which were quite sophisticated and in Chinese. As you know, the majority of the DataOx team is located in Ukraine, but we found a specialist who knows the language, and the most sophisticated captchas were solved manually by our Chinese-speaking colleague.
Pagination
Depending on site scope and specifics, pagination may be used, but the great number of pages caused problems for our work.
On Tmall, for instance, the pagination runs into a cyclic path after the 10th page. Thus, we had to scrape details in small groups, going from one product to another.
On JD, we faced trouble with sorting after the 10th page. We only needed fresh reviews to scrape, but due to this issue, we scraped all the reviews and then sorted them out to take 100-200 fresh comments.
Data scope
As we mentioned above, the scope of comments scraped in a session was numbered in the tens of millions. To manage all this data, we needed a dedicated system. The DataOx development team created a Kubernetes-based cluster using the Rancher system. The combination of those two technologies resulted in a quick and efficient data management system.
Design changes
Even though we develop universal scrapers for our projects and only significant redesigns can interfere with its work, different coding of the pages became a challenge for us. Depending on the situation, we either used a smart parser or an instrument dealing with a specific page structure.
Data quality
Data quality maintenance is always a challenge for extensive projects; but when you scrape information in Chinese, everything gets even more complicated. However, for our team, it was yet one more interesting task to complete, and we did it: we integrated a translator into our UI tech system.
Result
Our client was satisfied with our work, which exceeded his initial expectations for DataOx. The initial goals of the project were achieved and the due optimizations were implemented by our client's marketing team.
As you can see, getting access, scraping, and processing this data is a tremendous feat, but it offers a number of specific benefits. Let’s explore these a bit.
Benefits of Ecommerce Web Scraping
Web data scraping allows entrepreneurs to gather business intelligence quickly and efficiently while providing them with a bird’s-eye view of the market they operate in, including up-to-date business conditions, prevailing trends, customer preferences, competitor strategies, and challenges of lead generation. Through e-commerce websites, scraping businesses most often pursue the following aims:
Brand/reputation monitoring
Huge e-commerce platforms are a perfect source for researching the consumer attitude toward a chosen brand, whether it’s your company or a product you are going to sell. Through the web scraping of eCommerce websites, you can literally be all ears to what your target and real customers say and complain about, thus detecting their pain points and addressing them in a timely manner.
Customer preferences research
Directly listening to your consumers through reviews and feedback allows you to determine the crucial factors that drive sales in your market segment. By extracting and analyzing reviews with the right goals, your business can address its target audience’s needs, contribute to their satisfaction, garner more customers, and enhance sales.
Competitor analysis
Checking your brand reputation and listening to the customer’s voice is not enough. By monitoring your competitors, you can spot the hanging fruits you failed to see earlier. Scraping competitor product reviews can help you detect customer demand for a particular feature and become a pioneer in incorporating it into your product or service.
Fraud detection
Counterfeit goods are a threat to brands, influencing not only sales but also damaging brand reputation when a customer does not realize he’s got a fake. By scraping e-commerce sites for reviews, you can spot hints of ongoing fraud or identify partners/competitors who do not stick to their agreements. Web data scraping is an ideal solution to access a massive amount of product information and reviews all at once. Let’s find out why.
Why is Web Scraping Ideal for Product Information Extraction from Ecommerce Platforms?
When you need information about the product you are going to market, it’s impossible to manually extract all the details and reviews due to the enormous scope of data available. Plus, such work makes information prone to human errors, while automated data extraction is much faster, more efficient, and works at a large scale. Check out how to take data from a website below.
A software tool is able to browse thousands of product listings and capture the necessary details – pricing, a number of variants, reviews, or something else – in a matter of hours.
What’s more, scraping technology allows extracting details, which are invisible to a user’s eye or protected from common copy-pasting.
Another benefit of a technology solution is saving data into readable and meaningful formats convenient for processing and analysis.
What Kind of Data Can You Scrape?
The type of data you scrape is predetermined by your aims, so to scrape data from an e-commerce website and benefit from it, you need to understand the web data and the goals you set.
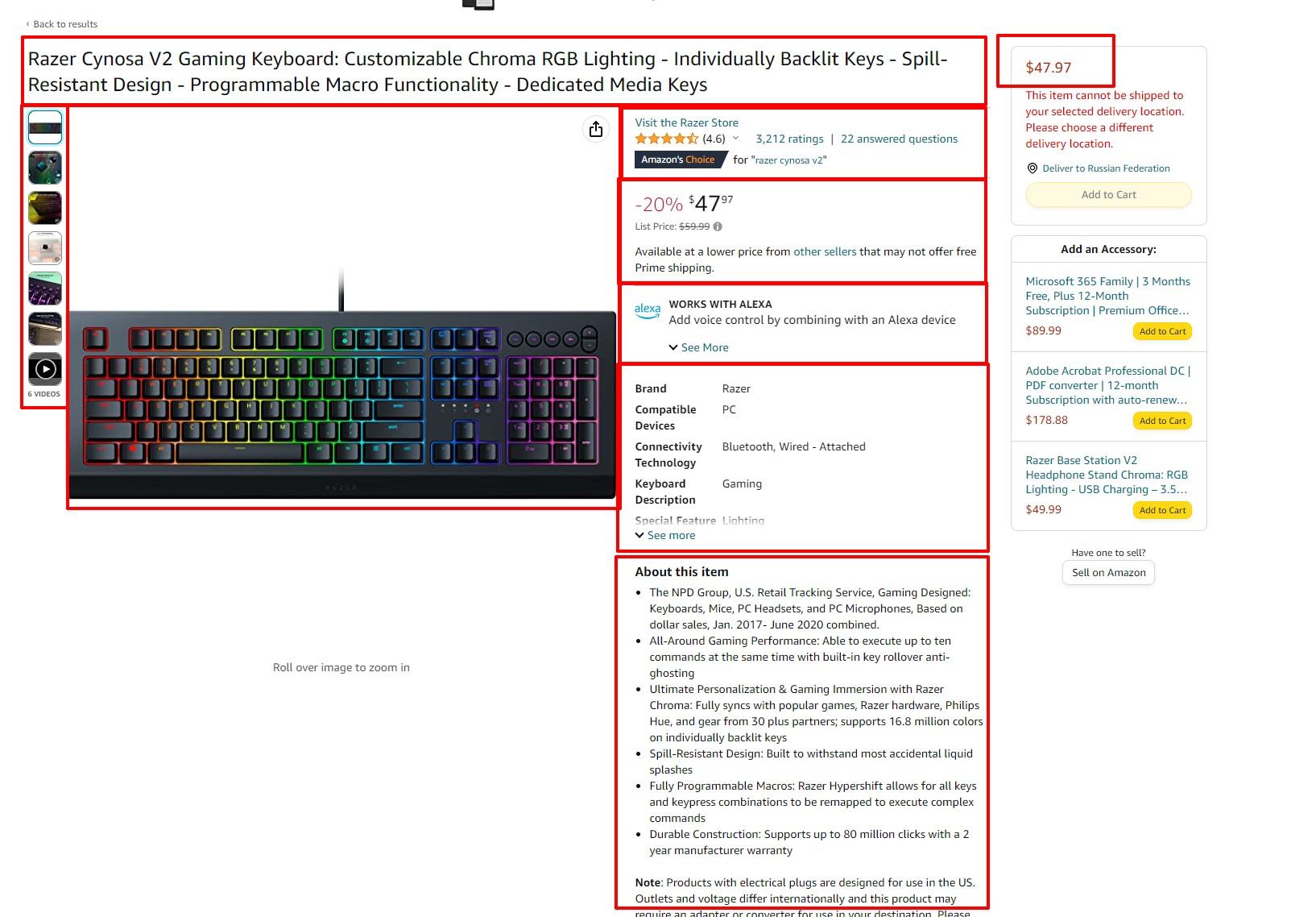
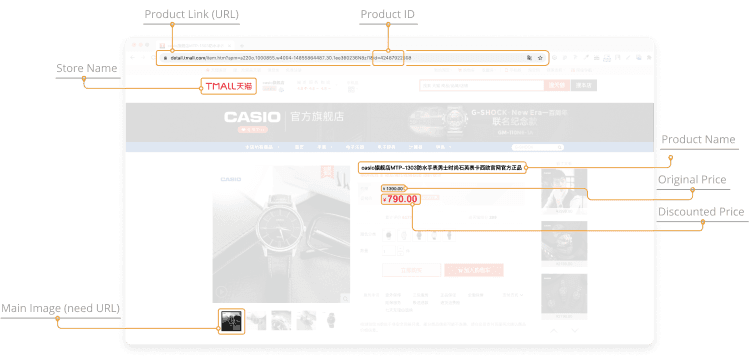
Let’s take a common e-commerce platform like Amazon. From it, we can scrape:
- Product URL
- Breadcrumbs
- Name of a product
- Item description
- Price
- Discount
- Stock details
- Image URL
- Average rating
- Product reviews
However, knowing what data can be scraped is not enough; you should know how to scrape products from eCommerce platforms efficiently. When you need to scrape 20 large sites and data from 25-30 subcategories within one category, you’re looking at 500+ requests. Additionally, the categories are often refreshed with a variable frequency, either daily, once in two or three days, weekly, etc. There can also be up to 10,000 reviews for a single product, meaning more than 10,000 requests to scrape them. Besides, sites don’t like to be scraped, so anti-scraping techniques should be considered in advance.
All these factors, combined with specific requirements as to legal compliance guidelines or internal operation optimization, result in a complex process made up of multiple activities and a corresponding budget.
Chinese Ecommerce Sites Data Extraction Challenges
As we’ve mentioned above, sites don’t like being parsed; their development teams and website admins do their best to prevent information from being extracted. However, a good web scraping specialist always knows what to do.
Awareness of common data scraping challenges allows you to automate and improve certain parts of the process using various digital solutions powered by machine learning technology or artificial intelligence.

Common, well-known obstacles to smooth scraping include:
- Webpage design and layout changes;
- Unique elements usage;
- Anti-scraping technologies utilized;
- HoneyPot traps;
- Captchas.
However, the larger the scale of the project, the more difficulties come with data gathering and the more effort should be put toward its quality assurance. Here, you’ll face the following challenges:
Building a correct crawling path and collecting the necessary URLs
When dealing with multiple products from an e-commerce site, you need to accurately build a crawling path and a URL library for data extraction. All the necessary URLs should be considered, and identified as important for your case to be parsed, and scraped later.
Crafting an efficient scraper
The tip of the iceberg here is choosing the right language and API along with the framework and another technology stack. Then, infrastructure management and maintenance should be considered, as well as anti-measures for fingerprinting and site protection.
Though you may be tempted to develop separate spiders for each site, our best practice and advice is to have one bot developed with all the rules, schemes, page layouts, and nuances of target sites in mind. The more configurable your tool is, the better, although it may be complex, it will be easier to adjust and maintain in the future.
Creating a scalable architecture
When it comes to e-commerce, there is no doubt that the number of requests will increase as soon as you scale your project further on. Your crawling infrastructure will require scaling, as well. Thus, you need to develop the architecture in such a way that it can scrape millions of requests a day without a decrease in performance.
How to scrape Chinese web well?
First of all, you need to make sure that your tool can detect and scrape all the necessary product pages in the time set (often one day) and to it, you should:
Separate product discovery from product extraction
Let separate tools discover the information and extract it. While the first should navigate to the necessary category and store the appropriate URLs to the special queue, the second should extract info from those product pages.
Allocate more resources to extraction
Naturally, a product category has up to 100 separate items, so extracting the details of each item consumes more resources than its URL. Therefore, you should not only separate discovery bots from extraction bots, but you should also have multiple scrapers for a certain amount of pages.
Maintaining throughput performance
When scraping e-commerce sites at a large scale, you should always look out for ways to minimize the time of the request cycle and maximize scrape performance. For this purpose, your development team should have a profound understanding of the scraping framework, as well as hardware and proxy management.
It’s also essential to maintain proper crawling efficiency and make sure the spider extracts only the data needed with as few requests as possible so that additional requests do not slow the site crawling pace. Try to fetch the product data right from the shelf page and do not extract images without necessity.
Scrape Chinese web taking anti-bot countermeasures
When scraping Chinese eCommerce sites, you’ll always run into sites that employ anti-bot countermeasures. While you’ll face basic ones on smaller sites, larger eCommerce platforms will offer you more sophisticated solutions and will most likely complicate your data extraction process significantly.
Proxy IPs and beyond
The common answers to this challenge to scrape Chinese web are proxies. When scraping at scale, you need to have an extensive list of proxies and a workable mechanism for their rotation, session management, and request throttling. In case you do not have enough resources to manage your own proxies, plenty of third-party services are now represented in the market with varying levels of proxy service. So, you can choose the option that best matches your project and tasks.
However, using a proxy service alone will not be enough. You must look for anti-bot countermeasures beyond this option.
Data quality
Data quality is the principal consideration of any web scraping task, and with large-scale projects, the focus on data quality should be even more severe. When you extract millions of data points in a single session, it’s impossible to manually verify its correctness. However, even a small drop in accuracy can disrupt your data analysis efforts and entail serious problems — not only to the scraping project but the entire business.
To ensure a high quality of extracted data, you need to apply quality assurance measures all throughout the data pipeline.
Most Common Errors
The most common data errors that we encounter in our projects are:
- Duplicates;
- Data validation errors;
- Coverage inconsistency;
- Product details errors.
First, you should make sure your spiders gather the right data from the right site sections and fields. Then, the extracted information needs to be checked with certain data validation algorithms for relevancy, consistency, accuracy, and correct formatting. The extracted information must meet predefined guidelines and pass the test frameworks of your project.
By the way, modern cutting-edge technologies of machine learning and artificial intelligence — when used in web scraping projects — can offer you an unparalleled competitive advantage over competitors, as well as save plenty of time and resources. More about data quality maintenance read here.
What’s Important to Consider to Scrape Chinese Web?
When scraping at scale, you should keep in mind that large eCommerce websites frequently change their structure, design, and pattern of categories and subcategories. You should have someone who is responsible for web scraping tool maintenance and timely adjustments to its code.
Unnoticed changes in site structure and consequent failure to make adjustments to the scraper in time may result in incomplete data results or, in the worst-case scenario, to scraper crash. To scrape Chinese web and ensure that the fetched data is of high quality, it’s reasonable to have a dedicated tool that will detect pattern changes on the site and notify the tech team about them.
When it comes to handling anti-scraping bots measures, it's not enough to rely on the IPs rotating to cope with the challenge; a dedicated person with a specific mind for research and finding out-of-the-box solutions to keep the tool running are essential.
As soon as the business team adds more categories or sites to the project, you should be ready to scale your scraping tools and overall data managing infrastructure accordingly.
When managing huge volumes of collected data, you should have either a proper data warehousing infrastructure developed in-house or a reliable cloud-based tool to deal with it.
Chinese Web Scraping FAQ
What is eCommerce scraping?
E-commerce site scraping is the process of extracting data that is important for companies to form a business plan, and understand a niche, critical market trends, product popularity, customer preferences, and competitor practices.
What is Chinese web scraping?
Scraping e-commerce sites from China can be problematic due to the following factors: requirements of Chinese IP addresses, access to the site only from mobile devices, captchas on each page, unpredictable pagination behavior, different design on typical pages, and work with the Chinese language.
How to scrape products from Chinese eCommerce websites?
For scraping information about products from e-commerce sites, the automatic method with the help of special software is best suited. The automatic method is optimal for several reasons: large volumes of data, many errors in manual scraping, detection of hidden or protected fields and products, and automatic saving of information in a convenient format.
Final Thoughts on How to Scrape Chinese Web
As you can now see from all the above-mentioned points, scraping e-commerce sites for product data at scale has its own unique set of challenges. However, there are workarounds to cope with them. Our team has enough enthusiasm, experience, and creative thinkers to extract product data at scale with ease.
Data quality is our priority and it is this that is valued by our customers since it allows them to beat competitors with informed marketing decisions. If you want to know more, schedule a free consultation with our expert and discuss your particular project and concerns.
Publishing date: Sun Apr 23 2023
Last update date: Wed Apr 19 2023