How to Extract Meta Data – Scrape Meta Titiles and Descriptions Easy
How to extract meta data and get meta titles and descriptions
from a website using web scraping tools.
Learn from DataOx experts!
Ask us to scrap the website and receive free data samle in XLSX, CSV, JSON or Google Sheet in 3 days
Scraping is the our field of expertise: we completed more than 800 scraping projects (including protected resources)
Table of contents
Estimated reading time: 5 minutes
Also popular posts

A Comprehensive Guide to Scrape Zillow with Python
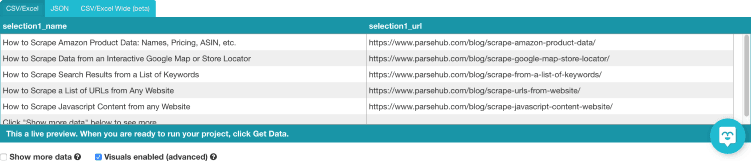
How to Download All URLs from a Website

Web Crawlers – Web Spiders Meaning, Types, Functions and Importance

Guide to Data Parsing: From Basic Principles to Practice

How to Take Competitive Advantages from Product Assortment Optimization Process
Introduction
Have you ever thought about why meta descriptions and title tags are essential for a website’s content? Thanks to keywords included in those tags, search engines understand what the website is about and index it.
This article will help you understand how to extract meta data, why to scrape title tags and meta descriptions, and how to do it using a metadata scraper.
What is a Meta Title?
The meta title applies to the HTML document’s title, which you see in the result of your search engines and on the website’s tab in browsers. The page title is a necessary element in the HTML code and is applied in the <head> section of the document.

The meta title is used to create the headings of items in the search result pages and might affect the number of clicks, thus ranking the web page. Besides, there are social media networks using the title as a heading while sharing the pages.
What is a Meta Description?
The meta description is an HTML tag, which describes what your website is. It will give you a chance to be noticed by search engines and bring users to your website. In other words, meta descriptions generate click-through rates coming from search engines.

Unfortunately, there is not always a chance that Google will show up your meta description, but it's always worth the effort to add it to your post.
Why Use Meta Scraper to Extract Meta Data
You’ve heard a lot about how data scraping can strengthen your marketing strategy. Extracting meta data can be one of the methods that you can use. For example, you can do some keyword research and find inspiration for new ideas.
Besides, SEO ranking is based on meta titles and descriptions; that’s why you can find out the genuine success of your competitors by extracting organic search results.

Meta data scraper is used to extract targeted URLs and scrape the websites’ titles, meta descriptions, and keywords. You can extract meta data from your competitors’ websites and make a further comparison.
Meet ParseHub: A Powerful Meta Data Scraper
ParseHub is an automatic and easy-to-learn tool for data extraction that can also extract meta titles and descriptions into a JSON or CSV file.
Now we’re going to extract the meta title and description of each post from Shopify. Before getting into business, download and install the ParseHub desktop app.
Setting Up a Meta Scraping Project to Extract Meta Data
To set up your project, go through the following steps:
- Open ParseHub.
- Click on New Project and insert the URL of the target page. The page will show up.
- Select the first blog post by clicking on its headline. Then select on the second blog post.
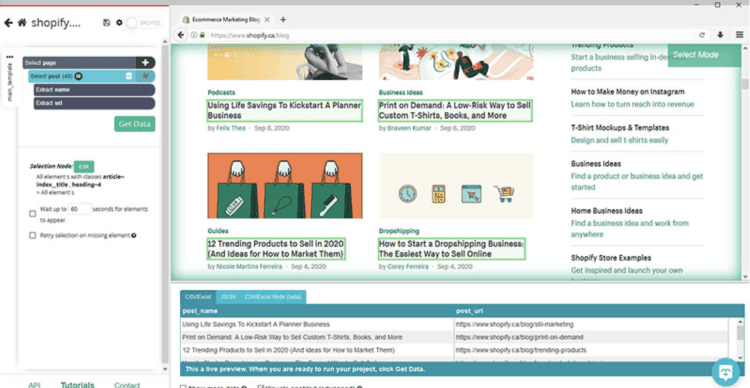
- Change the name of your selection to “post” on the left sidebar.
- ParseHub is now extracting the headline and URL for each post.
- Click on the (+) button and select the “Click” command.
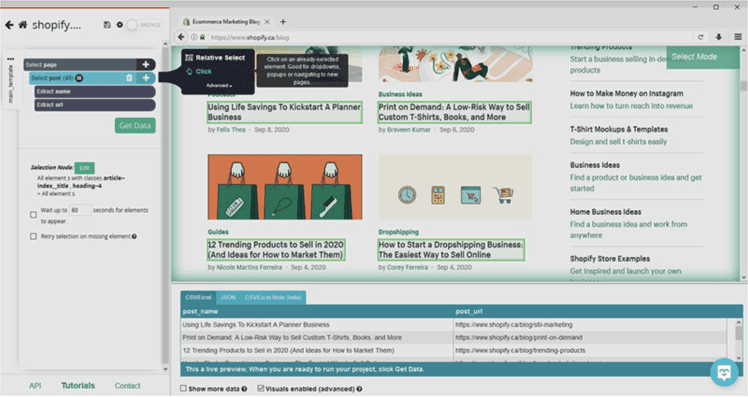
- A pop-up window will open. Click “No” and type a name for a new template: “blog_post”. Then click on the “Create New Template” button.
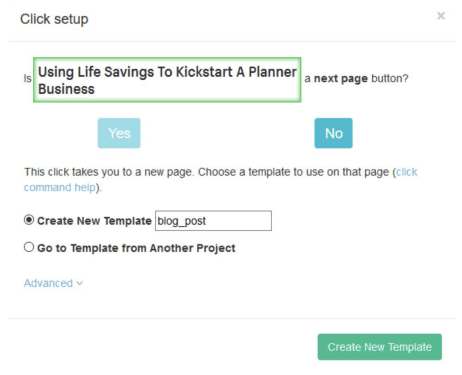
- The first blog will be rendered in the app, and the select command will be created.
Getting the Meta Title and Description
Now, let’s extract the meta title and description from every blog post. We’ll start by inspecting the code to define the two tags that we will fetch: <title> and <meta name=”description”>.
- Use the select command to select the post’s headline and rename it to “title”.
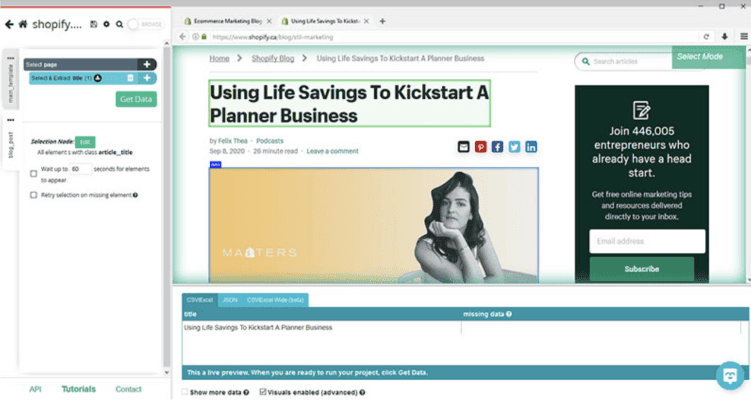
- Click on the “Edit” button and select the “use XPath selection” option.
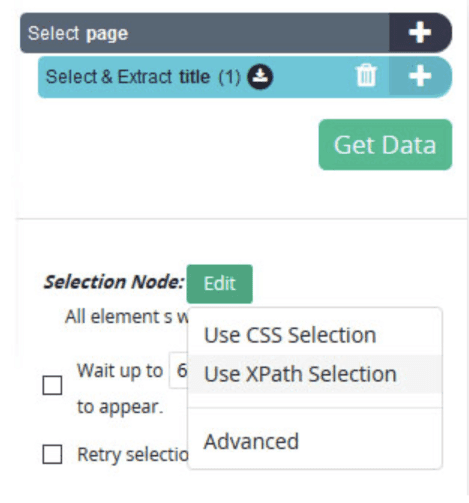
- In a newly appeared text field, ask ParseHub to extract the title.
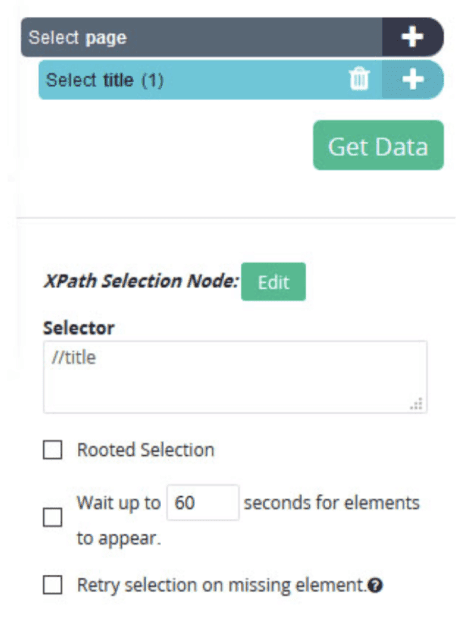
- Click on the (+) button, then click on “Advanced” and select the “Extract”.
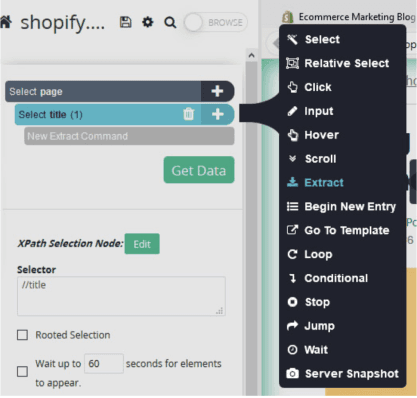
- From the drop-down menu, choose the “Inner HTML” option, and ParseHub will start to extract the meta title of each page.
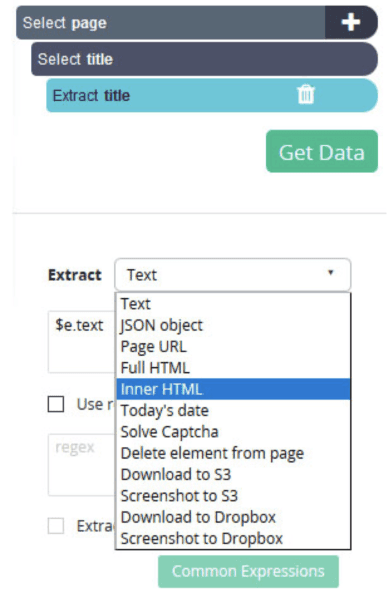
- Then click on the (+) button and add a new “select” command and repeat steps 1-6 to extract the meta description for the page.
- For the Xpath command, use: //meta[contains(@name,’description’)] since there is over one meta field.
- From the Extract command drop-down, select “content Attribute”.
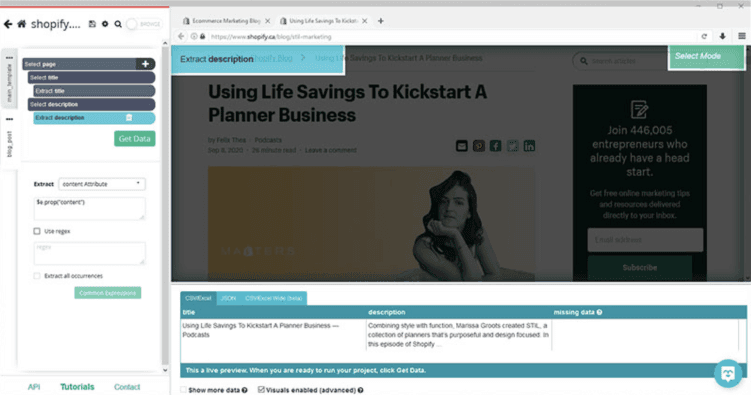
Running your Meta Scraper
Once you’ve completed all your setups, you can run your meta scraping job. Click on the Get Data button, and ParseHub will extract the requested data. When the extraction part is over, download the data in a CSV or JSON file.
Key Benefits of Scraping Meta Data
In the end, look through what kind of benefits you can have by scraping meta data:
- Extract keywords driving traffic to a website.
- Get which content is attracting links.
- Analyze and get valuable insights for better user engagement.
- Gain resources to increase your website rankings.
- Do competitor’s meta-data research.
How to Extract Meta Data – FAQ
To get the page's meta tags, you can use the Ctrl+U combination, open the page source code and look for <title> and <meta name=”description” tags, the text in these tags represents the URL's meta title and meta description. For faster checking, you can install a free browser plugin, like Meta SEO Inspector for Google Chrome. It checks and displays the meta tags with a click.
What meta title and description extractors are there?
There are browser extensions like Meta SEO Inspector, and SEO META in 1 Click, allowing on-page metadata check and extraction. You can also use online crawlers like Meta Tags Extractor, SeRanking, and Semrush; or desktop crawlers like Screaming Frog.
How to extract meta data from websites?
If you need to extract metadata for multiple pages (URL list crawl) or whole websites, use SEO crawlers. The best free solution is a Screaming Frog desktop crawler. It has a free version to crawl up to 500 URLs which is enough for small websites. Other alternatives are Netpeak Spider, JetOctopus, etc.
Conclusion
The meta and description tags attract readers to a website from the search engine results, which is a significant part of search marketing. So, by scraping the metadata of your competitors, you can identify their click-through rate potential and make a valuable analysis. If web scraping seems complicated for you, you can always hire professionals like a DataOx team.
DataOx is an experienced web scraping provider, always ready to help you with any data scraping project. Schedule a free consultation with our expert to learn how DataOx can help you with your business development through web scraping.
Publishing date: Sun Apr 23 2023
Last update date: Wed Apr 19 2023