

As you can see, many scraping services on the web can do all the hard work for you. You have to choose the right one.
How To Scrape A Glassdoor With Coding?
With programming knowledge, you will not have to deal with intermediaries (not considering the technical nuances like a proxy server) and pay for something you can create yourself. Scraping a Glassdoor website using various programming languages and libraries, such as Python, Beautiful Soup, and Selenium. Here are some steps to follow:
- Install the necessary software. To start, you must install Python and the necessary libraries, such as BeautifulSoup and Selenium. You can install these libraries using pip, a package manager for Python.
- Understand the website structure. Before you start scraping, you need to understand the structure of the Glassdoor website. This involves identifying the HTML tags and attributes that contain the data you want to scrape.
- Write the code. Once you understand the website structure, you can start writing the code. This typically involves using libraries like BeautifulSoup to parse the HTML code and extract the relevant data. If you need to interact with the website, you may also need to use a library like Selenium to automate user interactions.
- Test the code. After writing the code, test it on a small sample of data to ensure it works correctly. This will also help you identify any errors or bugs in the code.
- Scale up the scraping. Once you have tested the code, you can scale up the scraping to extract data from the entire website. This may involve using loops and other programming constructs to automate the scraping process.
- Store the data. After scraping the data, store it in a format that is easy to analyze, such as CSV or JSON. You can also store the data in a database for easier management and analysis.
Next, you will see some code examples for BeautifulSoup and Selenium.
Scrape Glassdoor using BeautifulSoup
Here is a detailed guide on how to scrape Glassdoor using Beautiful Soup:
1. First, make sure you have the required libraries installed. You will need Beautiful Soup, requests, and pandas. You can install these using the following command:

2. Next, import the libraries into your Python script:

3. Define the URL of the Glassdoor page you want to scrape. For example, if you want to scrape job listings in New York City for the keyword “data scientist,” you could use the following URL:

4. Use the requests library to retrieve the HTML content of the page:

5. Use Beautiful Soup to parse the HTML content:

6. Use the Chrome Developer Tools or a similar tool to inspect the page and identify the HTML tags and classes that contain the data you want to scrape. For example, if you want to scrape the job titles, you could use the following code:

This code finds all the <div> tags with the class ‘jobHeader’, then finds all the <a> tags with the class ‘jobLink’ within those <div> tags, and extracts the text of the <a> tags. It then adds the text to the job_titles list.
Repeat step 6 for any other data you want to scrape, such as company names, salaries, and job locations. 7. Once you have scraped all the data you want, you can store it in a pandas DataFrame:

This code creates a DataFrame with the job titles, companies, salaries, and locations as columns. 8. You can then save the DataFrame to a CSV file:

This code saves the DataFrame to a file named ‘glassdoor_jobs.csv’.
Glassdoor Scraper on Selenium
This is a small guide on how to scrape Glassdoor with Selenium.
Prerequisites
Before starting, make sure that you have the following:
- Python 3 installed on your machine.
- Selenium package installed on your machine.
- Chrome or Firefox browser installed on your machine.
- Chrome or Firefox webdriver installed on your machine.
- Glassdoor account.
Step 1: Import the Required Libraries
First, you need to import the necessary libraries in our Python script. In this case, you will need the Selenium and time libraries.

Step 2: Set Up the Browser and Login
Next, set up the browser and log in to Glassdoor. First, instantiate a new instance of the browser using the webdriver module. Then navigate to the Glassdoor login page and enter credentials.
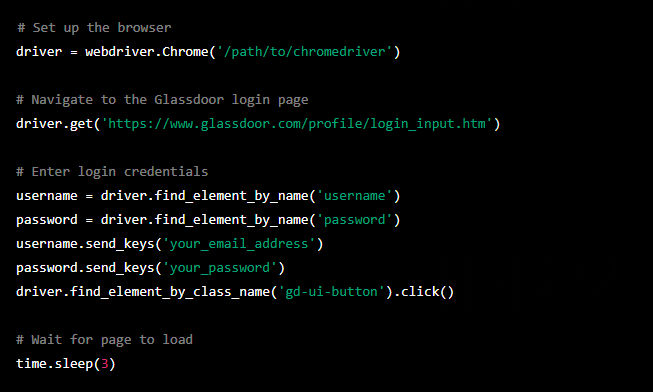
Note that you will need to replace ‘/path/to/chromedriver’ with the path to your Chrome or Firefox webdriver.
Step 3: Search for Jobs
Once you have logged in, you can search for jobs on Glassdoor. To do this, navigate to the job search page and enter these search criteria.
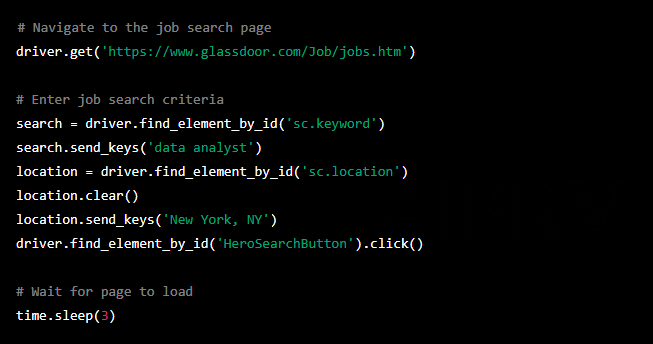
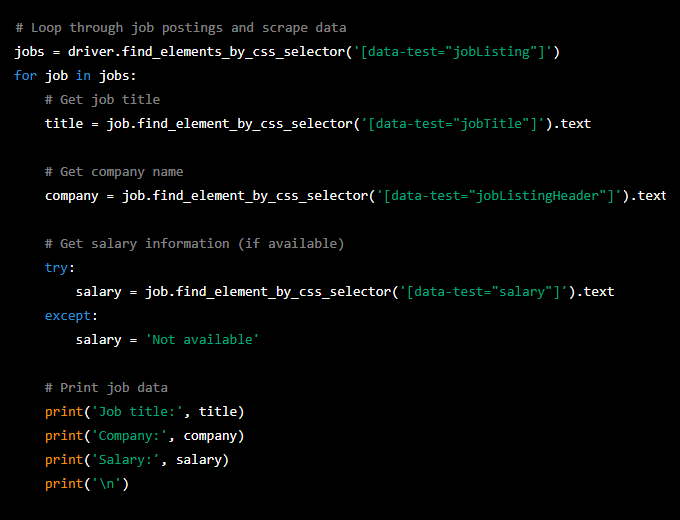
Step 4: Scrape Job Data
Now that you have performed a job search, you can scrape data on the job postings. You need to loop through each job posting on the page and extract the job title, company name, and salary information (if available).
Step 5: Close the Browser
Finally, close the browser to end the session.

That’s it! Note that this is just a basic example, and you can modify the script to scrape additional data or perform more complex searches.
Conclusion
So, web scraping Glassdoor can be an efficient and effective way to collect valuable data for businesses and researchers. By following these steps and using the right web scraping tools, you can automate data collection and analysis, saving time and improving accuracy.
Consequently, you have a choice: do the scraping with your own strength and skills, or use ready-made solutions from popular services. Whatever you choose, it is essential to consider that the extracted data’s speed, quality, and reliability depend on the experience and the necessary tools.
Would you like to learn more about Glassdoor scraping and benefit from the expertise of our experts? Contact us for a free consultation.









