Back to blog
Alibaba Web Scraping: Tutorial on How to Scrape Product & Seller Data



Challenge: LegalTech startup needed compliant data collection...
SEE HOW WE SAVED 70% OF MANUAL EFFORT
Your Position
CEO/Founder
CTO/Tech Lead
Data Analyst
Legal Counsel
Business Owner
Other
Main challenge
Manual data collection takes too much time
Need to scale data operations
Legal compliance concerns
Data quality and accuracy issues
Integration with existing systems
Other
Company Size
Startup (1-10 employees)
Small business (11-50)
Medium business (51-200)
Enterprise (200+)
Get case study
When you collect product data from huge e-commerce websites like Alibaba you get a great opportunity to do comprehensive competitive research, market analysis, and price comparison. It is one of the leading e-commerce portals with an enormous product catalog. However, Alibaba web scraping is a real challenge if you are not familiar with data collection infrastructure. This article will allow you to find out why use Alibaba scraper and how to scrape Alibaba product data through Scrapy — one of the most widely used open-source frameworks for web scraping.
3 Reasons to Scrape Alibaba
Data extracted from e-commerce websites is a potential help. to businesses in e-commerce industry and not only. Keep reading to learn three main reasons why you need to scrape data from Alibaba.

1. Cataloging and listing
For any e-commerce business listing and cataloging competitors’ products are the most important thing. Without an up-to-date and comprehensive product list, it is impossible to compete in the e-commerce market. So, using Alibaba extractor, you can easily get Alibaba info and build your own product list based on your target audience’s demands and preferences or even create a new category of products.

2. Marketplace analytics
To do complete market research companies strive to get insights from the buyers’ feedbacks like ratings and reviews. This user-generated content will give you a clear sign of a particular product or brand. This kind of data can be used to improve your current products or offer a new one as well as build a positive brand reputation.

3. Prices monitoring
Today Alibaba is well known for its affordable prices, that is why it is crucial to extract its prices for further price comparison and optimization. Almost all e-commerce users are tracking product prices, and Alibaba may be the most popular source to track in the first turn. So, if you want to know prices in the market to optimize your price strategy, start with Alibaba scraping!

How to Create an Alibaba Crawler
Written in Python, Scrapy is one of the most efficient free frameworks for web scraping that enables users to extract, manage, and store information in a structured data format. It is perfectly adapted for web crawlers extracting details from various pages. Let’s move forward to learn how to scrape Alibaba — leading marketplace data.
Scrape Alibaba — Getting started
To create an Alibaba scraper you need to have Python 3 and PIP. Follow the links to download them:
- Windows: https://www.scrapehero.com/how-to-install-python3-in-windows-10/</a >
- Linux: http://docs.python-guide.org/en/latest/starting/install3/linux/</a >
- Mac: http://docs.python-guide.org/en/latest/starting/install3/osx/</a >
To install the necessary packages, the following command is used:
pip3 install scrapy selectorlib
Creating Alibaba Scrapy project
The next step is to create a Scrapy project for Alibaba with the scrapy_alibaba folder name containing all necessary files. The command is the following:
scrapy startproject scrapy_alibaba
Creating the crawler
There is a built-in command in Scrapy called genspider that is responsible for generating the primary crawling template.
scrapy genspider <spidername> <website>
To generate our crawler that will create spiders/scrapy_alibaba.py file it should be:
scrapy genspider alibaba_crawler alibaba.com
The complete code should look like:
import scrapy
import csv
import os
from selectorlib import Extractor
class AlibabaSpider(scrapy.Spider): name = “alibaba_crawler” allowed_domains = [“alibaba.com”]
custom_settings = { # Override the default Scrapy user agent to avoid immediate detection “USER_AGENT”: ( “Mozilla/5.0 (Windows NT 10.0; Win64; x64) ” “AppleWebKit/537.36 (KHTML, like Gecko) ” “Chrome/120.0.0.0 Safari/537.36”
), # Alibaba’s robots.txt disallows /trade/ paths used for search. # Set to False only if you have reviewed the ToS and have a # legitimate business reason to proceed. “ROBOTSTXT_OBEY”: False, # Add a delay between requests to reduce detection risk “DOWNLOAD_DELAY”: 2, “RANDOMIZE_DOWNLOAD_DELAY”: True,
} def start_requests(self): e = Extractor.from_yaml_file( os.path.join(os.path.dirname(__file__), “../resources/search_results.yml”) )
keywords_file = os.path.join( os.path.dirname(__file__), “../resources/keywords.csv” ) with open(keywords_file) as f: reader = csv.DictReader(f) for row in reader: search_text = row[“keyword”] url = ( “https://www.alibaba.com/trade/search” f”?fsb=y&IndexArea=product_en&CatId=&SearchText={search_text}&viewtype=G” ) yield scrapy.Request( url, callback=self.parse_listing, meta={“search_text”: search_text, “extractor”: e},
) def parse_listing(self, response): e = response.meta[“extractor”] data = e.extract(response.text) if data and data.get(“products”): for product in data[“products”]: yield product
Note: Alibaba actively uses anti-bot protection. Even with a custom User-Agent, scrapers are frequently detected when scraping at large scale. Residential proxy rotation is highly recommended to maintain reliable access at scale. DataOx handles anti-bot issues as part of every Alibaba scraping project.
Scrape Alibaba Product Data
In this example, we are going to extract the following fields for the earphones:
- Name of the product
- Price
- Image
- Link to the product
- Minimum number of orders
- Name of the seller
- The response rate of the seller
- Number of years as a seller on Alibaba
To extract the required data from Alibaba we’re going through the following 3 steps:
- Create a Selectorlib library
- Create a keyword file
- Export data in the required format
Creating a Selectorlib pattern for Alibaba
Selectorlib is a Chrome extension enabling users to point out the required data and create CSS Selectors or XPaths to extract that data. To learn more about Selectorlib go to the following link. Below you may find how we point out the fields in the code for the required data we need to extract from Alibaba using Selectorlib.
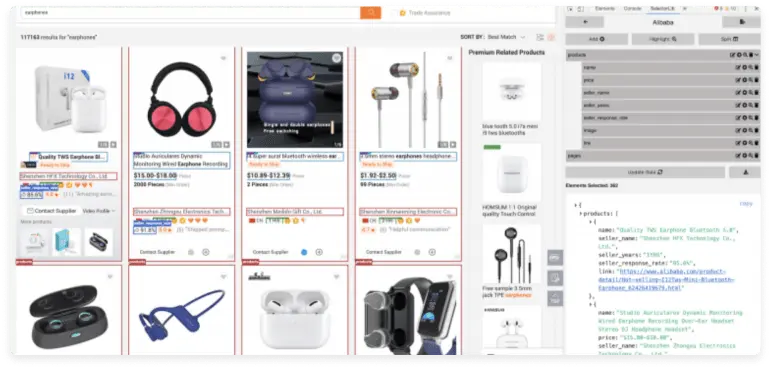
Below is the current YAML selector file for Alibaba search results. Alibaba updates its HTML structure periodically, so always re-inspect selectors in DevTools before running the crawler to confirm they still return data:
products:
css: ‘div.fy23-search-card’
multiple: true
type: Text
children:
name:
css: ‘h2.search-card-e-title span’
type: Text
price:
css: ‘div.search-card-e-price-main’
type: Text
seller_name:
css: ‘a.search-card-e-company’
type: Text
link:
css: ‘a.search-card-e-slider__link’
type: Link
min_order:
css: ‘div.search-card-m-sale-features__item’
type: TextWhen you marked all the required data, click on the Export button to download the YAML file and save it as search_results.yml in the folder named /resources.
Reading keywords
Now we’re going to set up the Alibaba scraper to read specific keywords from a certain file placed in the folder /resources. Let’s create there a CSV file named keywords.csv and use Python’s CSV module to read our keywords file.
keyword
headphones
earplugs
The crawler reads this file in the start_requests method shown in the crawler code above, using Python’s standard CSV module to iterate over each keyword and build the search URL.
def parse(self, response):
“””Function to read keywords from keywords file”””
keywords = csv.DictReader(open(os.path.join(os.path.dirname(file), “../resources/keywords.csv”)))
for keyword in keywords:
search_text = keyword[“keyword”]
url = “https://www.alibaba.com/trade/search?fsb=y&IndexArea=product_en&CatId=&SearchText={0}&viewtype=G”.format(search_text)
yield scrapy.Request(url, callback=self.parse_listing,
meta={“search_text”: search_text})
Exporting data into CSV or JSON
With Scrapy you can have in-built JSON and CSV formats. To save the extracted data in the desired format just use the appropriate command line.
scrapy crawl alibaba_crawler -o alibaba.csv -t csv
scrapy crawl alibaba_crawler -o alibaba.json -t json
The output will be saved in the same folder as the script.
Alibaba Scraper: Alternative Method
To sum up, we can state that creating the Alibaba scraper is not an easy task. So, if you make up your mind to outsource Alibaba product data extraction to a dedicated web scraping service, a provider like DataOx will free you of the complications in web crawling.
Schedule a free consultation with our expert to reveal the whole list of our web scraping services and learn how DataOx can help you to scrape Alibaba product data on a large scale.

web scraping services
Get free consultation
FAQ: How to Scrape Alibaba
Is Alibaba web scraping legal?
Publicly available product data (listings, prices, seller names, and ratings visible to any site visitor without login) is a legally accessible target in most jurisdictions. Personal data, authenticated content, and bulk resale of scraped datasets create much higher legal exposure. DataOx responsibly reviews the legality of every Alibaba scraping project before starting: zero legal incidents across 10+ years of experience serve as a confirmation!
Why does my Alibaba scraper get blocked even with a custom User-Agent?
A realistic User-Agent with a datacenter IP still fails, because the IP itself signals automation. Scrapy’s default DOWNLOAD_DELAY also produces request timing patterns that do not look like a real browser session. To reduce detection risk, DataOx recommends using residential proxy rotation, randomized delays, and consistent header sets together. For high-volume scrape Alibaba product data projects, DataOx handles the infrastructure of data collection and provides structured, consistent data delivery specifically for your needs — you do not have to handle the anti-bot layer yourself.
What data can actually be extracted from Alibaba with a Python scraper?
Product names, price range, minimum order quantity, seller name, seller rating, and the product URL can be extracted from search result pages. Full descriptions, specifications, images, supplier contact details, delivery options can be obtained from individual product pages. Selectorlib YAML targets these fields through CSS selectors like h2.search-card-e-title span for product names and div.search-card-e-price-main for prices.
How often do Alibaba's CSS selectors break?
A scraper left unattended for a few months will typically stop returning data. Alibaba updates its frontend regularly, and class names like fy23-search-card or search-card-e-company are not permanent identifiers. This is why you should re-inspect the live page in DevTools for changes. DataOx is able to maintain all Alibaba scraping pipelines it builds, updating selectors when Alibaba changes its structure or protection methods.
Can I use Scrapy for large-scale Alibaba scraping without getting banned?
Scrapy alone is not enough at large scale. For teams that need continuous, large-volume Alibaba scrapers without building and maintaining it internally, DataOx runs the full pipeline — from collection to structured delivery in CSV, JSON, or directly into a database.
Stay ahead with data insights
Subscribe to DataOx newsletter




get a free consultation
Fill out the form — we'll get back to you with options tailored to your needs.
what happens next
We review your goals and get in touch to clarify scope
Your privacy is a priority — NDA available upon request.
You receive a clear proposal with timeline, budget, and delivery format.
Once approved, we start building your data pipeline.
contact us
Let's find the best solution for your data needs.

get a free consultation
Fill out the form — we'll get back to you with options tailored to your needs.
what happens next
We review your goals and get in touch to clarify scope
Your privacy is a priority — NDA available upon request.
You receive a clear proposal with timeline, budget, and delivery format.
Once approved, we start building your data pipeline.
contact us
Let's find the best solution for your data needs.