Back to blog
Scrape Zillow Data Python Method: All You Need to Know


Introduction
The real estate market is one of the most dynamic fields, where data scraping plays a major role not only for real estate business owners and agencies but also for regular customers. When we need to make the decision regarding buying or renting properties, the first thing we should do is a comparative analysis based on price, type of house, its size, location, etc.

Therefore, we’re going to scrape the leading real estate marketplace called Zillow. There are several paid Zillow data scrapers in the market that you can buy and use, but in this article, we are going to scrape Zillow with the help of Python. So, if you have some coding skills and do not want to pay the extra money, let’s move forward to learn how to download data from Zillow.

Why Choose Python
As we’ve mentioned above, if you have some coding skills and a bit of knowledge about web scraping, then you can develop your Zillow data scraper to extract the required data from Zillow. You can use any programming language to handle HTML files, but Python is widely used for developing scrapers. Some facts:

- BeautifulSoup and Scrapy are the most popular scraping-friendly frameworks based on Python.
- BeautifulSoup library provides a fast and highly effective data extraction.
- Python supports XPath.
- Great idioms are provided for searching, navigating, and modifying the parse tree.
- Other advanced web scraping libraries are available.
Scraping Zillow Using Python and LXML
Python tools you will need
For scraping Zillow with Python, it is required to have Python 3 and Pip installed. Follow the instructions below for the purpose
- For Linux users: http://docs.python-guide.org/en/latest/starting/install3/linux/
- For Mac users: http://docs.python-guide.org/en/latest/starting/install3/osx/
- Windows users go here: https://www.scrapehero.com/how-to-install-python3-in-windows-10/
As we are using Python 3, it is also required to install the following packages for downloading and parsing the HTML code. Here are the package requirements:
- To install the packages, we need PIP – installation
- To download the HTML content, we need Python Requests – installation of requests
- To parse the HTML Tree Structure, it is required Python LXML – lxml installation
Common steps
We are going to search and scrape Zillow data based on a specific postal code: 02128.
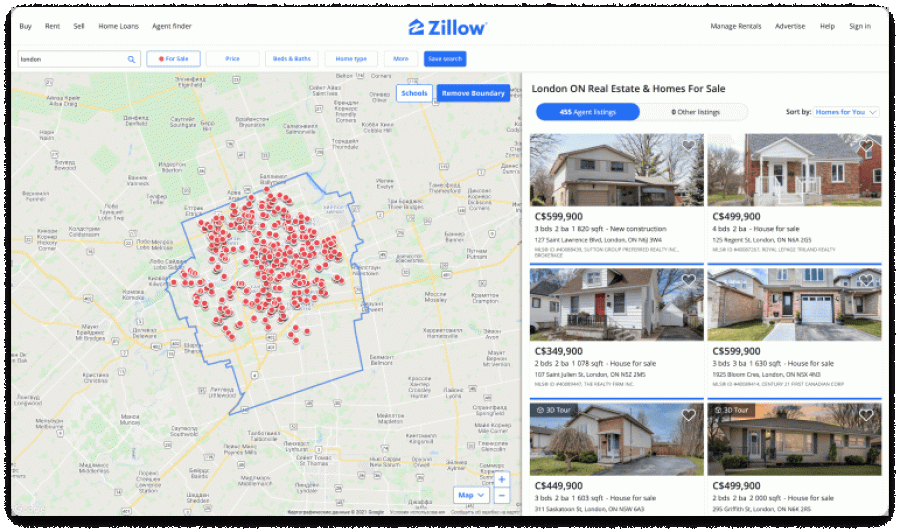
The whole scraping process contains the following steps:
- Conduct a search on Zillow by inserting the postal code.
- Get the search results URL: https://www.zillow.com/homes/02128_rb/.
- Download HTML code through Python Requests.
- Parse the page through LXML.
- Export the extracted data to a CSV file.
Running the Zillow data scraper
Let’s name the script zillow.py that will be used for the script name in a command line.

So, to get the newest listings, we should run an appropriate script to sort the relevant arguments for the specific zip code.

In the final step, a CSV file will be created in the same folder as the script.
Scrape Zillow Using Python and BeautifulSoup
In this part, we’ll just go through some useful insights that you can use while scraping Zillow.
Required libraries
For BeautifulSoup you need to install the required libraries, which can be done through the requirements.txt file. Just input the complete list in the file and run the pip install requirements.txt file.

Bypassing captchas
Like many websites, Zillow also throws captchas. That’s why while deploying a request.get(url) function, it is required to add headers to the request function. See the below example:

Looping through URLs
To create variables, there are many ways to loop through URLs. Let’s try the simplest one. So, if you are planning to extract 5 pages’ data, you can create 5 soup variables and give them a unique title as in the below example.

Formatting data
To make the extracted data more readable, just make some formatting jobs. So, we are going to:
- Convert columns
- Rearrange columns
- Drop null rows

Conclusion
Once you decide to scrape Zillow keep in mind that it uses anti-scraping techniques like captchas, IP blocking, and honeypot traps to prevent its data from scraping. Already skilled scraper builders can overcome them, but for newbies, it can be a challenge. For teams that prefer a fully managed approach, DataOx offers a professional Zillow web scraping service without the proxy headaches.
At DataOx we are always happy to help you with professional advice regarding extracting real estate data or offer you a customized Zillow scraper that would meet your business needs.
Schedule a free consultation with our expert and find out how web scraping can help your real estate business grow.

web scraping services
Get free consultation
FAQ: A Comprehensive Guide to Scrape Zillow with Python
Is it possible to scrape Zillow data with Python without getting blocked?
It is possible but not guaranteed. A proper User-Agent header and referer value will allow you to pass the first layer. Beyond that, Zillow runs serious bot detection that indicate datacenter IPs almost immediately. For anything beyond a one-time test, it is crucial to use rotating residential proxies and request pacing. DataOx builds Zillow scrapers with all of that handled at the infrastructure level — you get clean data without managing the blocking triggers yourself.
What data can a Python Zillow scraper actually extract?
Mostly following public listing pages: property address, price, number of beds and baths, square footage, days on market, and listing URLs. The data-test attributes — property-card-price and property-card-addr — are the most stable selectors for scrape Zillow data Python projects right now. Agent details, Zestimates, and price history are also accessible but require scraping individual property pages. DataOx scopes the exact field set before writing code, so nothing gets missed.
How often does Zillow change its HTML structure?
Scrapers frequently break without warning — no selector is permanent, and additionally, Zillow regularly updates its protection measures. Upon clients request, DataOx maintains Zillow web scraper Python pipelines it builds and fixes broken selectors in a short time to maximize stability of our solutions.
Can a Zillow data scraper handle multiple ZIP codes or cities at once?
Yes — that is, in essence, a loop. The scraper iterates through a list of ZIP codes or city slugs, builds the URL dynamically for each, and collects results into a single dataset. The real obstacle is request volume: hitting too many pages in a short window triggers rate limiting. DataOx structures multi-location scraping sessions with proper delays, overall management, and proxy rotation so the scraper runs at scale without triggering blocks in the middle of the process.
Is scraping Zillow legal?
Publicly available listing data — prices, addresses, property details visible to any site visitor — is generally considered legal to scrape in most jurisdictions. The line is drawn at data behind authentication, personally identifiable information, and content Zillow explicitly restricts in its Terms of Service. DataOx reviews the legality of every real estate scraping project before it starts.
Stay ahead with data insights
Subscribe to DataOx newsletter




get a free consultation
Fill out the form — we'll get back to you with options tailored to your needs.
what happens next
We review your goals and get in touch to clarify scope
Your privacy is a priority — NDA available upon request.
You receive a clear proposal with timeline, budget, and delivery format.
Once approved, we start building your data pipeline.
contact us
Let's find the best solution for your data needs.

get a free consultation
Fill out the form — we'll get back to you with options tailored to your needs.
what happens next
We review your goals and get in touch to clarify scope
Your privacy is a priority — NDA available upon request.
You receive a clear proposal with timeline, budget, and delivery format.
Once approved, we start building your data pipeline.
contact us
Let's find the best solution for your data needs.