A Comprehensive Guide to Scrape Zillow with Python
Learn how to scrape Zillow using Python.
Need professional help with scraping
real estate data? Ask DataOx’s experts!
Ask us to scrap the website and receive free data samle in XLSX, CSV, JSON or Google Sheet in 3 days
Scraping is the our field of expertise: we completed more than 800 scraping projects (including protected resources)
Table of contents
Estimated reading time: 4 minutes




Introduction
The real estate market is one of the most dynamic fields, where data scraping plays a major role not only for real estate business owners and agencies but also for regular customers. When we need to make the decision regarding buying or renting properties, the first thing we should do is a comparative analysis based on price, type of house, its size, location, etc.

Therefore, we’re going to scrape the leading real estate marketplace called Zillow. There are several paid Zillow data scrapers in the market that you can buy and use, but in this article, we are going to scrape Zillow with the help of Python. So, if you have some coding skills and do not want to pay the extra money, let’s move forward to learn how to download data from Zillow.

Why Choose Python
As we’ve mentioned above, if you have some coding skills and a bit of knowledge about web scraping, then you can develop your Zillow data scraper to extract the required data from Zillow. You can use any programming language to handle HTML files, but Python is widely used for developing scrapers. Some facts:

- BeautifulSoup and Scrapy are the most popular scraping-friendly frameworks based on Python.
- BeautifulSoup library provides a fast and highly effective data extraction.
- Python supports XPath.
- Great idioms are provided for searching, navigating, and modifying the parse tree.
- Other advanced web scraping libraries are available.
Scraping Zillow Using Python and LXML
Python tools you will need
For scraping Zillow with Python, it is required to have Python 3 and Pip installed. Follow the instructions below for the purpose
- For Linux users: http://docs.python-guide.org/en/latest/starting/install3/linux/
- For Mac users: http://docs.python-guide.org/en/latest/starting/install3/osx/
- Windows users go here: https://www.scrapehero.com/how-to-install-python3-in-windows-10/
As we are using Python 3, it is also required to install the following packages for downloading and parsing the HTML code. Here are the package requirements:
- To install the packages, we need PIP – https://pip.pypa.io/en/stable/installing/
- To download the HTML content, we need Python Requests – http://docs.python-requests.org/en/master/user/install/
- To parse the HTML Tree Structure, it is required Python LXML – https://lxml.de/installation.html
Common steps
We are going to search and scrape Zillow data based on a specific postal code: 02128.
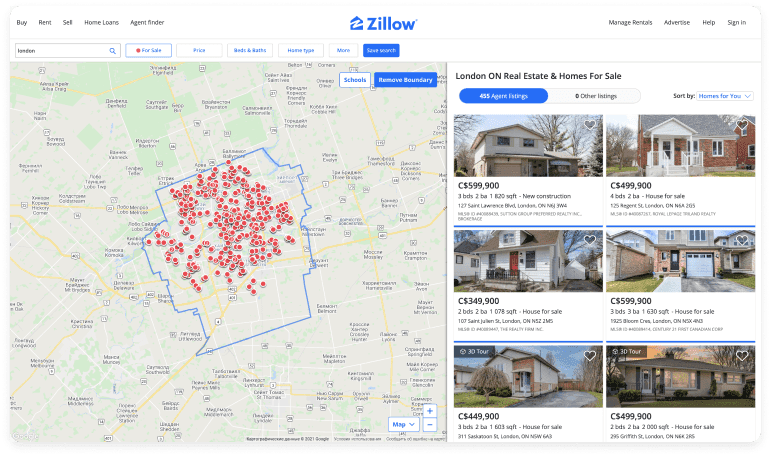
The whole scraping process contains the following steps:
- Conduct a search on Zillow by inserting the postal code.
- Get the search results URL: https://www.zillow.com/homes/02128_rb/.
- Download HTML code through Python Requests.
- Parse the page through LXML.
- Export the extracted data to a CSV file.
Running the Zillow data scraper
Let’s name the script zillow.py that will be used for the script name in a command line.

So, to get the newest listings, we should run an appropriate script to sort the relevant arguments for the specific zip code.

In the final step, a CSV file will be created in the same folder as the script.
Scrape Zillow Using Python and BeautifulSoup
In this part, we’ll just go through some useful insights that you can use while scraping Zillow.
Required libraries
For BeautifulSoup you need to install the required libraries, which can be done through the requirements.txt file. Just input the complete list in the file and run the pip install requirements.txt file.

Bypassing captchas
Like many websites, Zillow also throws captchas. That’s why while deploying a request.get(url) function, it is required to add headers to the request function. See the below example:

Looping through URLs
To create variables, there are many ways to loop through URLs. Let’s try the simplest one. So, if you are planning to extract 5 pages’ data, you can create 5 soup variables and give them a unique title as in the below example.

Formatting data
To make the extracted data more readable, just make some formatting jobs. So, we are going to:
- Convert columns
- Rearrange columns
- Drop null rows

Frequently Asked Questions
How to scrape data from Zillow?
Download HTML pages using Python, parse them with LXML to extract the necessary data, and import them to CSV. If you don’t have coding skills, use online services or Data OX developers’ help.
How to download Zillow data?
Create API requests using Python or other development tools.
How to use Zillow API?
Create an account, get a free Zillow web services ID (access token) to access API, and make API calls with preferred developer tools.
Where does Zillow get its data?
Zillow gets data about the real estate properties at local municipal offices, the National Association of Realtors, and the State Department of Real Estate. All data is processed via MySQL Cluster.
Summary
Once you decide to scrape Zillow keep in mind that it uses anti-scraping techniques like captchas, IP blocking, and honeypot traps to prevent its data from scraping. Already skilled scraper builders can overcome them, but for newbies, it can be a challenge.
At DataOx we are always happy to help you with professional advice regarding extracting real estate data or offer you a customized Zillow scraper that would meet your business needs.
Schedule a free consultation with our expert and find out how web scraping can help your real estate business grow.
Publishing date: Sun Apr 23 2023
Last update date: Tue Apr 18 2023