Reddit Image Scraper – How to Download Reddit Images with ParseHub
Read and learn how to scrape images from the Reddit website
using a ParseHub Reddit Image scraper.
Learn from DataOx experts!
Ask us to scrape the website and receive free data sample in XLSX, CSV, JSON or Google Sheet in 3 days
Scraping is the our field of expertise: we completed more than 800 scraping projects (including protected resources)
Table of contents
Estimated reading time: 5 minutes





Introduction to Reddit Scraping
Reddit is a web source where you can scrape many social data from comments to images and videos. So, if you are interested in social data scraping, Reddit might be an incredible source for you, as it is the number one forum where you can explore a subreddit for any topic.

There are various Reddit scrapers available in the market today, so you are free to choose the most suitable one. In this article, we’ll learn how to collect images from Reddit using a scraper from ParseHub.
Scraping Reddit Data
To get publically available data from Reddit, you can use the authorized Reddit API for free. However, please keep in mind that it was not made for scraping purposes, so you can face some limitations that you can overcome only by using a professional web scraper.

So, scraping the Reddit website requires software programs like web scrapers to enable data extraction. Anyway, while collecting data from Reddit using scrapers, be aware that Reddit does not approve their usage, and this is considered a violation of the website's terms of usage. Yet, it does not mean that downloading from Reddit is illegal.
ParseHub: a Reddit Downloader
In today's market, ParseHub is known as one of the most popular web scrapers. It is a web scraping instrument used to crawl and extract data from any website, even those that are using AJAX and JavaScript. ParseHub offers a ready Reddit scraper that can be used for scraping images from Reddit web pages.

Before scraping images from Reddit, you need to download the ParseHub desktop app and Tab Save Chrome browser extension.
Getting Started with Image Scraping
Now, let’s go through the steps needed to scrape images:
- Run ParseHub and start a New Project. Paste the URL of the subreddit page you are going to scrape.
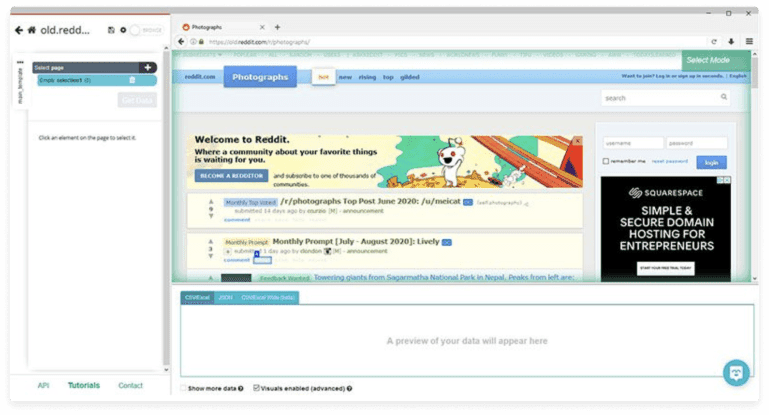
- Select the posts that should be scrapped. The chosen parts will be highlighted in green.
- Change the name of your selection to “posts”.
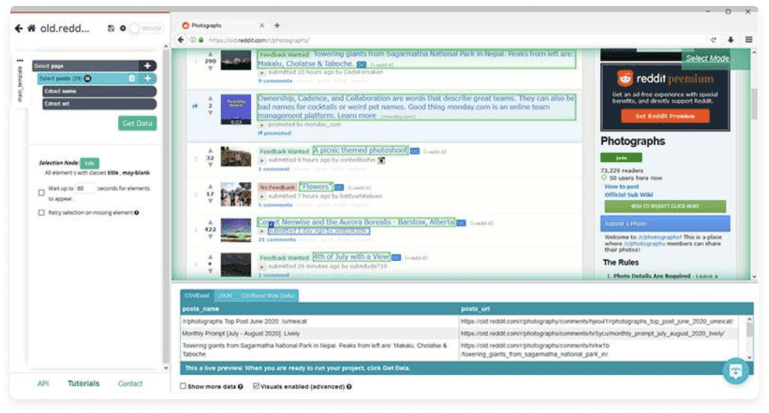
- ParseHub is starting to scrape data from every post along with links and titles, though we only need direct links to the images. So we have to delete these unnecessary parts from our scraping project.
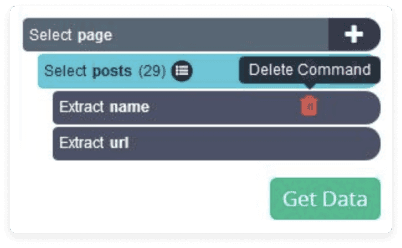
- Now, we’ll make ParseHub go through each post and extract only the URL of the image. Click on the (+) button and choose the Click command.
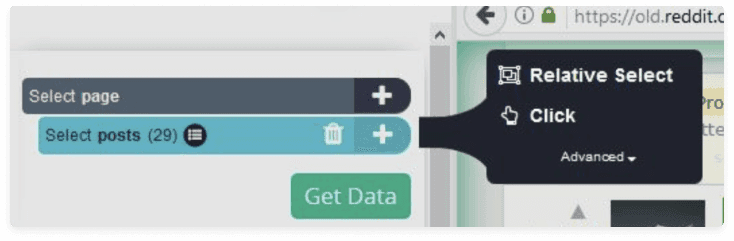
- On the opened pop-up window, click on the No button and create a new template by changing the name to posts_template.
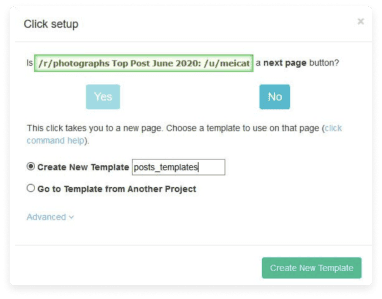
- Now click on the image to scrape its URL.
- A new selection will be created, so you need to rename it to the image. Expand it and delete the image extraction. So only the image_url extraction will be left.
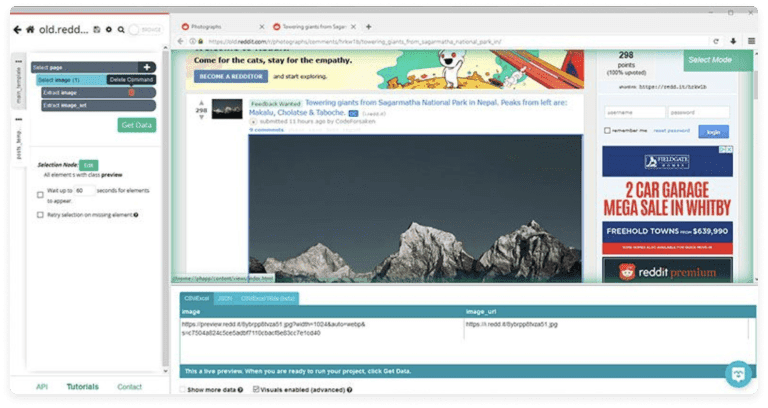
Dealing with Pagination
Once you have finished extracting the URLs of the images from the first page, you can go on to other pages as well.
- Go to the subreddit page and select your main_template.
- Click on the (+) button and choose the Click command.
- Scroll to the bottom of the page and go to the next link. Change the name of the selection to next. Expand it and delete both extractions.
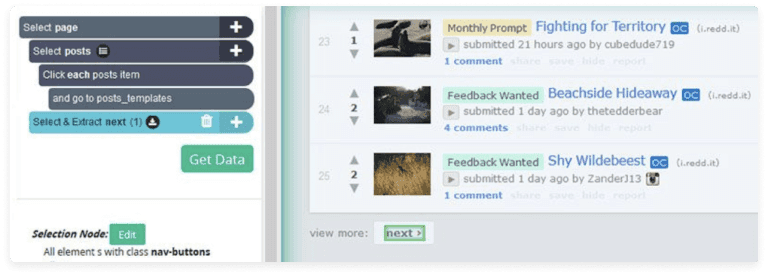
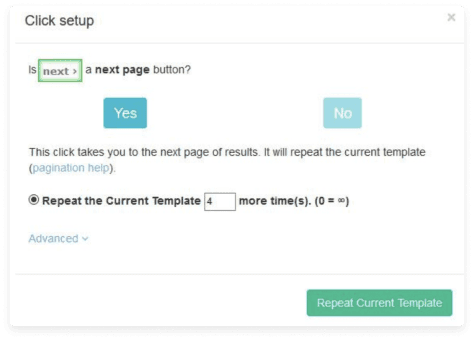
- Click on the (+) button one more time and choose the Click command.
- On the opened pop-up window, click on the Yes button and enter the number how many times it is required to repeat this process.
Running the Reddit Image Scraper
Once all required setups are made, it’s time to run our scraper and extract the image URLs. Click on the "Get Data" button to test, schedule, and run your image scraping project. Once the scraping part is over, you can start to download them in a preferred format: JSON or CVS file.
Downloading Images
After extracting the list of URLs, it’s time to download the images. Here Tab Save Chrome browser extension comes into play:
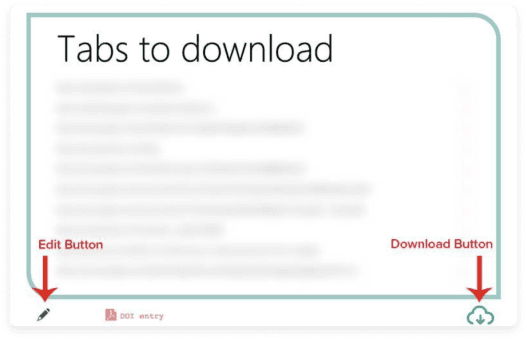
- Run the extension.
- Click on the Edit button and copy-paste the URLs you need to download. These URLs are available in your ParseHub export.
- Click on the Download button to save them on your device.
Challenges of Scraping Reddit Data
Reddit is a well-structured website, but it is not user-friendly enough for data scraping. Here are the key challenges to take on when using Reddit image scraper:
- The necessity to apply browser automation to extract data.
- Browsing large threads requires multiple clicks.
- The Reddit API support only a specific number of requests per minute.
Reddit Image Scraper FAQ
What Reddit image scrapers are there?
There are several online scrapers allowing to export of images from Reddit. Those are ParseHub, Octoparse, Apify, and OctoParse. Each of them has plans allowing us to scrape information from Reddit.
How to download images from Reddit?
You can download Reddit images manually from the app by clicking on the three dots near the image and choosing the "Download" option. If you use the desktop site version, right-click on the image and choose "Download". If you need to download multiple images – use online scraping tools or professional DataOx developers’ help.
How to scrape Reddit comments?
If you have some coding skills, you can use Python to scrap comments and posts from Reddit. Out-of-the-box options are available in ParseHub packages. It allows scraping the r/deals subreddit (the old Reddit version) which has access to API. For starters, you choose a particular post, enter its URL to a ParseHub project and start a standard scraping process.
Reddit Image Scraper Conclusion
Scraping Reddit can be challenging for people who are unfamiliar with web scraping nuances and have no resources for coding. Anyway, if you decide to scrape Reddit data, you can always order your scraping needs from companies providing web scraping services.
An experienced web scraping provider like DataOx is always ready to help you with any scraping job. Schedule a free consultation with our expert to reveal the complete list of our web scraping services and learn how DataOx can help you boost your business through web scraping.
Publishing date: Sun Apr 23 2023
Last update date: Wed Apr 19 2023