Back to blog
Web Scraping Login Required Pages: Avoid Limitations


Scrape Data from Website with Login
We know that data requiring a login to access is not public as a rule, which means that sharing, using, and web scraping login required pages for commercial purposes can be illegal. Hence, before scraping data from such web sources, you should always check the legality.
In web scraping, collecting data from web sources that require login is one of the common issues. So what can you do about it? Keep reading, and you will learn how to scrape data from a website with login using ParseHub.

Want to Scrape Data from Website with Login? Check It First
If you are thinking about data scraping and want to handle it yourself by building a scraping bot or using data scraping tools, the first thing is to check the following points:
- Is it legal?
- Check the sitemap of the target website.
- Analyze the content and the size of the target website.
- Check copyright limitations.
- Choose where to store.
- Decide on scraping technology.
Login Required Free Web Scraping Tools: Introducing ParseHub
ParseHub is a powerful web scraper designed for data collection from many web sources like JavaScript or AJAX sites. It offers such features as scheduled scraping, IP rotation, attribute extraction, etc.
And of course, thanks to ParseHub, you can overcome the most common issues such as the web login screen that you might encounter while scraping.

First Steps
So, before starting to scrape websites that require passwords, follow the steps below:
Register a new Gmail account for your future scraping purposes.
Read the terms and conditions of the web source to protect you from further complexity because such restrictions usually have particular reasons.
Download and install the ParseHub tool from here.
How to Scrape Data from a Website with Login: ParseHub Technique
As an example of harvesting a page requiring authorization, we will consider Reddit.com.
Now you know how simple it is to skip any login web page while scraping using ParseHub, so you can go ahead with your scraping project as we did above.
1.Run ParseHub and enter the URL of the target website.
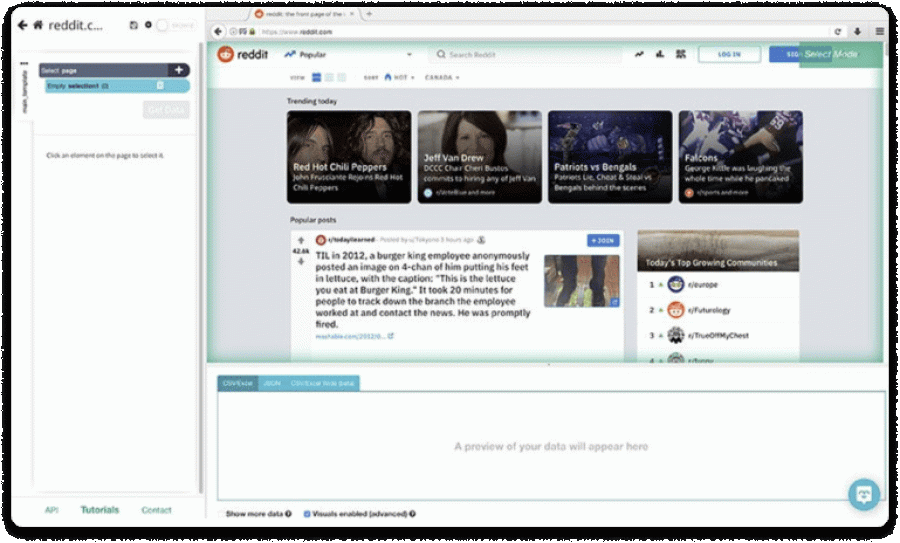
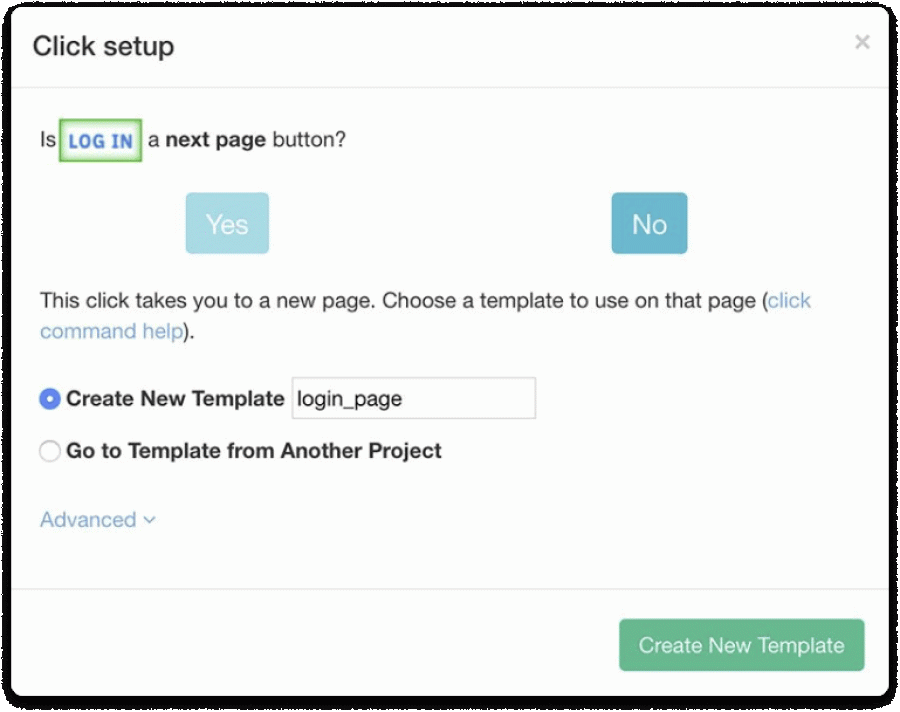
2. Select Log In button by clicking on it and rename it to login in the left sidebar. Click on the (+) button and select the Click command.

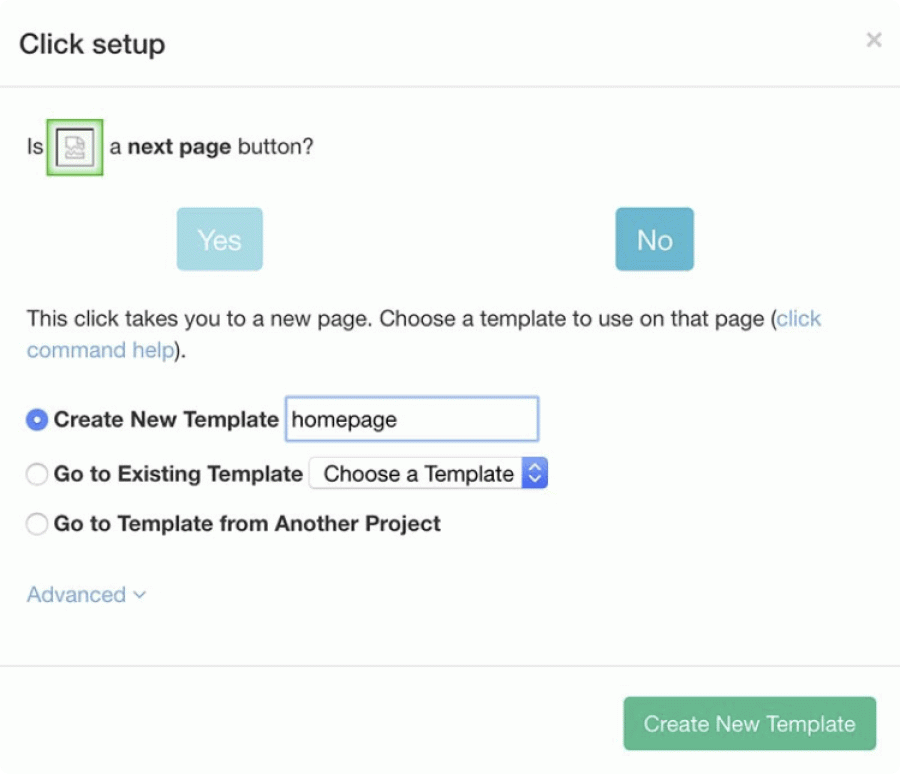
- In the pop-up window, click on the No button and create a new template by naming it the login_page. Then it will open a new browser tab and scrape the template.
- Click on the Username field, type your username, and change the selection name to a username.
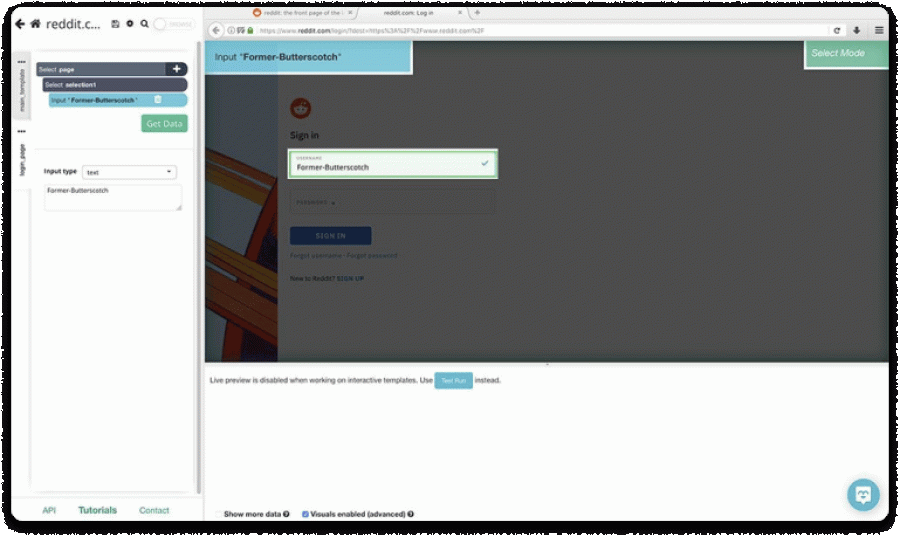
- Click on the (+) button and click on the Select command.
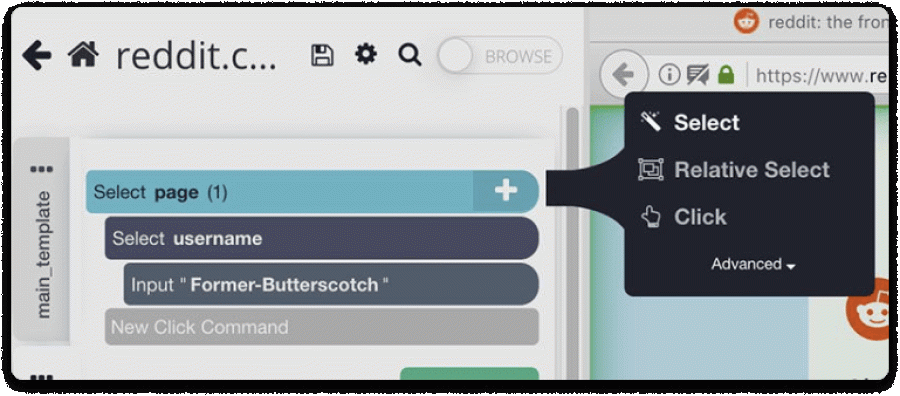
- Next, click on the Password field, enter your password, and change the name of the selection to password.
- Click on the (+) button and click on the Select command.
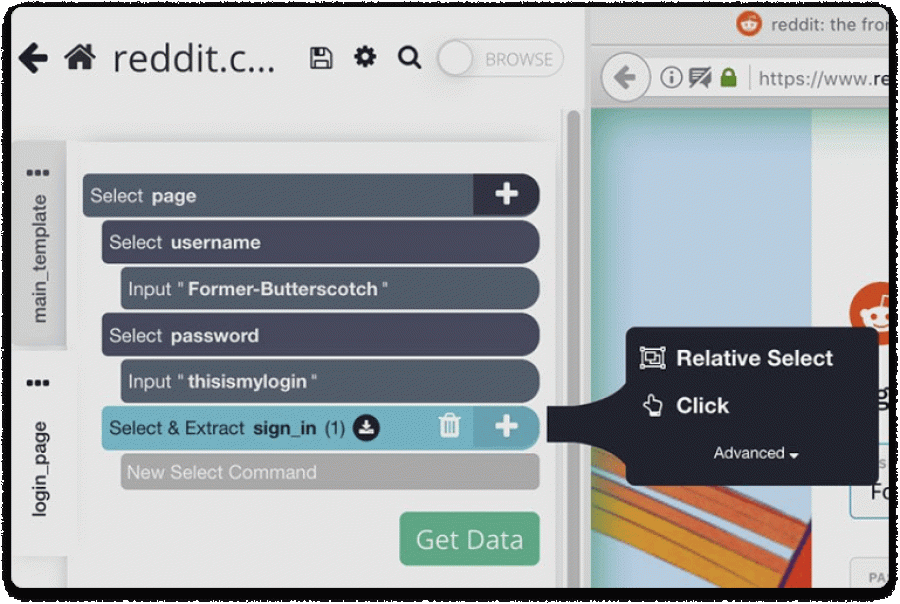
- The same we’ll do with Sign In. Click on Sign In and change the selection name correspondingly to sign_in.
- Click on the (+) button and click on the Click command.
- In the appeared pop-up window, click on No, and create a new template by naming it the homepage.
How to Copy Data from a Protected Web Page
Although your goal is to extract information for further data analysis and not plagiarism, you need to know that many websites are protected from copy-pasting their data. Check out the top methods to overcome this protection:
1.Taking a screenshot and extracting text from images.
2.Disabling JavaScript from browser settings;
3.Applying for special extensions;
4.Copying text from source code;
5.Using inspect elements;
Hiring Service Provider for Web Scraping Login Required Python & Custom Solutions
Many of the largest companies trust their scraping projects to data scraping service providers, mainly when the project implies such challenges as scraping at a scale, complex websites, or if the target pages require login.
Besides, most information that should be extracted is unstructured or protected via anti-scraping mechanisms. Additionally, legal issues should also be kept in mind. That is where a good service provider like DataOx comes into play — 300+ completed projects, zero legal incidents!
Closing Thoughts on Web Scraping with Login Required
So, if you are going to handle your web scraping project by yourself, keep in mind all challenges listed in the previous section. But, if you choose to trust it to professionals, keep in mind DataOx experts who are always ready to help you with any scraping job.
Schedule a free consultation with our expert to reveal the complete list of our web scraping services and learn how DataOx can help you scrape web sources that require login credentials.

web scraping services
Get free consultation
comment
Leave a Reply
FAQ about Web Scraping with Login Required
Is web scraping login required pages legal?
Data behind a login is not public by definition, which means commercial use of that data carries legal risk. Before any attempt to scrape data from a website with login, the terms and conditions of the target source require careful review, as well as copyright limitations and sitemap restrictions. DataOx always operates within legal boundaries — 300+ completed projects, zero legal incidents.
How to scrape data from a website with login without professional development experience?
Login required free web scraping tools like ParseHub are a reasonable starting point: it handles JavaScript and AJAX sites, includes IP rotation, and supports scheduled scraping without writing code. For simple sources, this covers the basic requirement. As for complex targets with multiple authentications or anti-scraping protection, DataOx builds custom solutions that handle these obstacles reliably.
How does web scraping login required Python solutions differ from no-code tools?
Python-based scraping gives full control over session handling, cookie management, and requests, which matters on complex authenticated targets. No-code tools cover standard complexity but struggle with dynamic authentication, multi-step verification, and JavaScript pages. Web scraping login required Python solutions are more precise and scalable. DataOx develops both custom Python scrapers and no-code applications, adapted to the technical complexity of the source.
What are the main obstacles when trying to scrape data from a website with login at scale?
We can highlight three main obstacles: anti-scraping mechanisms that detect and block automated sessions, unstructured data formats behind the login wall, and legal restrictions specific to the target platform. Unprepared teams typically fail at managing all three obstacles simultaneously, but DataOx can take ownership of the technical and legal complexity.
When does it make sense to hire a data scraping service provider instead of scraping login-required pages independently?
When the project involves scale, complex authentication, or data that requires structured post-processing (data delivery options, data visualization, etc.). Building and maintaining a scraper capable of handling login flows, anti-bot systems, and data formatting is a significant technical challenge. DataOx covers the full cycle: 1) extraction; 2) structuring; 3) maintenance, and 4) customer technical support by demand — so the client receives clean, usable data without managing the infrastructure behind it. Schedule a free consultation to discuss your specific case!
Stay ahead with data insights
Subscribe to DataOx newsletter




get a free consultation
Fill out the form — we'll get back to you with options tailored to your needs.
what happens next
We review your goals and get in touch to clarify scope
Your privacy is a priority — NDA available upon request.
You receive a clear proposal with timeline, budget, and delivery format.
Once approved, we start building your data pipeline.
contact us
Let's find the best solution for your data needs.

get a free consultation
Fill out the form — we'll get back to you with options tailored to your needs.
what happens next
We review your goals and get in touch to clarify scope
Your privacy is a priority — NDA available upon request.
You receive a clear proposal with timeline, budget, and delivery format.
Once approved, we start building your data pipeline.
contact us
Let's find the best solution for your data needs.
You are definitely right